You’re probably in one of two places right now. You’ve either spent months learning Python, SQL, and machine learning and still feel unqualified, or you’ve started applying and discovered that “entry-level” data jobs often don’t behave like entry-level jobs at all.
That confusion is normal. The path into a data science junior role is rarely clean. Job titles blur together, requirements drift, and the same old advice to “build projects and apply everywhere” stops working fast when every other applicant is doing exactly that.
The good news is that this field still offers real opportunity. The harder truth is that opportunity doesn’t automatically go to the most hardworking beginner. It often goes to the candidate who understands the unwritten rules: which skills matter first, how to present proof instead of claims, and how to apply before a role turns into a crowded public contest.
Your Path into the Booming Field of Data Science
If you want a first role in data, you’re not chasing a dead end. The demand is real. The U.S. Bureau of Labor Statistics projects that employment for data scientists will grow 34% from 2024 to 2034, with about 23,400 job openings annually, and notes entry-level salaries averaging around $95,000 to $110,000 in 2025 according to the BLS outlook for data scientists.
That should change your framing immediately. The question isn’t whether the field is worth entering. It is. The better question is whether you’re approaching the market the way hiring teams evaluate junior candidates.
What juniors get wrong early
Most beginners treat the process like school. They think the path is linear: finish courses, earn a certificate, build a couple of notebooks, submit applications, wait for a response. Hiring rarely works that way.
Managers don’t just ask, “Does this person know Python?” They ask:
- Can this person clean messy data without freezing
- Can they explain what they chose and why
- Can they work inside business constraints
- Can they communicate clearly when the result is imperfect
Those are very different questions from exam questions.
Practical rule: Your first job won’t go to the most “complete” junior. It often goes to the junior who looks easiest to trust.
That’s why the strongest candidates don’t optimize only for skill accumulation. They optimize for signal. They show usable projects, targeted applications, clear writing, and evidence that they can think through trade-offs.
The real goal of your first role
Your first role isn’t supposed to prove you’re a finished data scientist. It proves you can contribute without constant rescue.
That means a junior who can prepare a dataset properly, write sensible SQL, build a baseline model, create a clean chart, and explain caveats will often beat someone with a longer list of buzzwords and weaker judgment. Teams can train depth. They struggle to train ownership.
Here’s the shift that matters:
| Old mindset | Better mindset |
|---|---|
| I need to learn everything first | I need to become useful fast |
| I need more certificates | I need clearer evidence |
| I should apply everywhere | I should apply selectively and early |
| I need an impressive model | I need a convincing workflow |
If you keep that lens, everything else becomes simpler. Learn what companies hire for. Build proof around that. Package it well. Then use a search strategy that gives you a timing advantage, not just a bigger application count.
Foundational Skills for Your First Data Science Role
Most junior candidates make the same mistake. They build a giant shopping list of tools and then feel behind because they haven’t mastered all of them. That’s unnecessary.
For a first data science junior role, employers keep coming back to the same foundations. Key sectors hiring junior data scientists include tech (35%), financial services (22%), and healthcare (18%), and the most common foundational requirements are proficiency in R/Python, statistical analysis, and SQL for data preparation according to South Dakota Mines career guidance on data science roles.
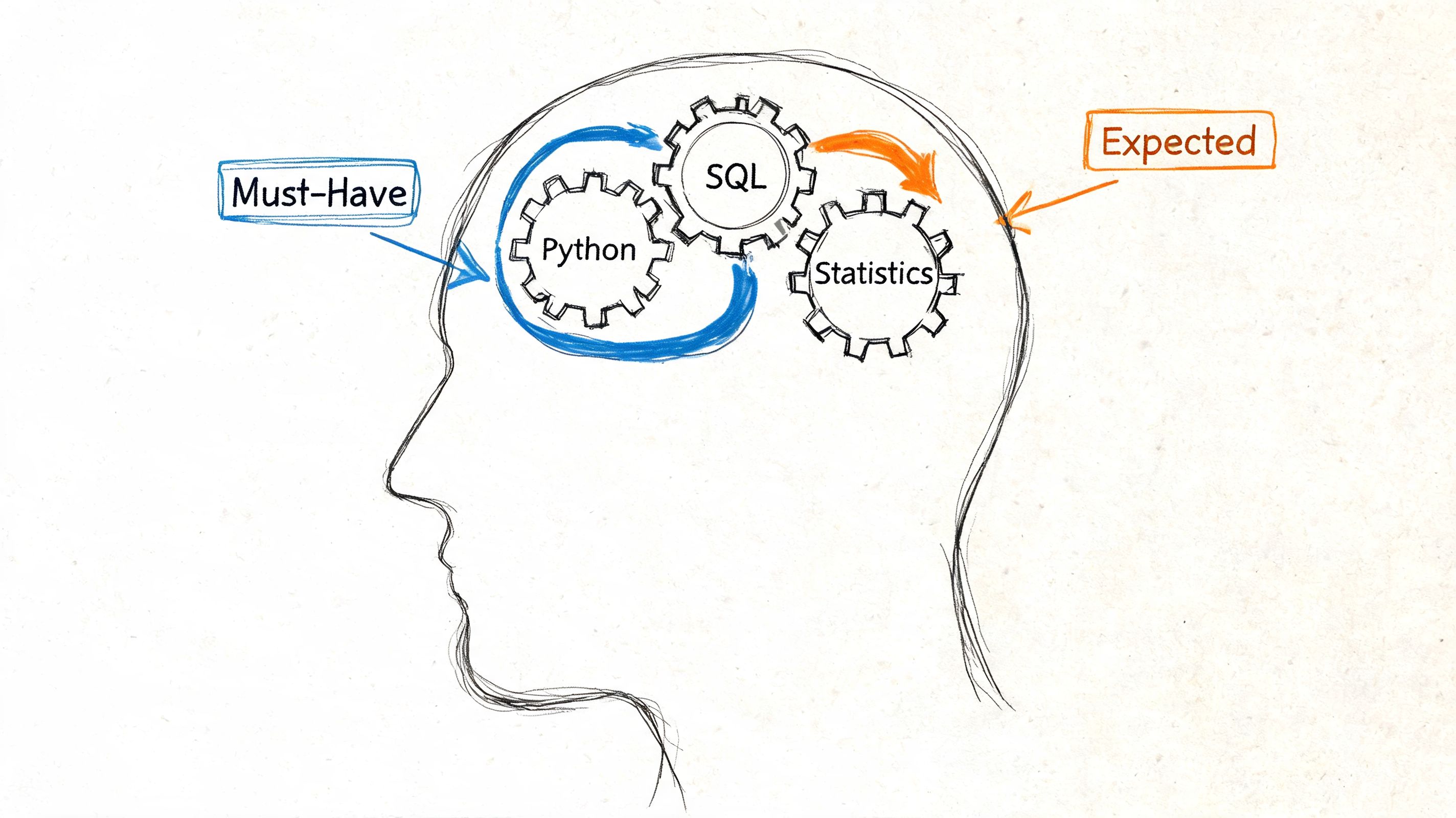
The three skills that actually carry you
If I were mentoring a beginner from scratch, I’d center the first phase on three areas.
Python that solves real work
You don’t need to know every library. You need enough Python to move confidently through a basic analysis workflow.
That means being comfortable with:
- Data loading and cleaning using pandas
- Exploration with filtering, grouping, joining, and missing-value handling
- Basic visualization with matplotlib or seaborn
- Simple modeling with scikit-learn
- Readable scripting instead of one giant notebook cell dump
A junior who can clean ugly data, produce a baseline model, and write clear code is already useful. A junior who can only run tutorial notebooks isn’t.
SQL that proves you can work with production-shaped data
SQL gets underestimated because it looks simpler than machine learning. In practice, weak SQL blocks a lot of junior candidates.
You should be able to:
- Select and filter correctly
- Join tables without guessing
- Aggregate with confidence
- Use window functions at a basic level
- Translate a business question into a query
If someone asks, “Which customer segments changed behavior after a product launch?” your job isn’t to reach for a fancy model first. It’s to pull the right data cleanly.
Statistics that guide decisions
Junior roles don’t require you to be a research scientist. They do require you to think statistically.
Know the meaning and practical use of:
- Distributions
- Sampling
- Bias and variance
- Correlation versus causation
- Evaluation metrics
- Confidence in results and common caveats
You should be able to explain why accuracy might be the wrong metric, why leakage ruins a model, or why a dataset doesn’t support a strong conclusion.
If you can’t explain your result in plain English, you probably don’t understand it well enough for an interview.
Nice to have versus need to have
A lot of juniors burn time on tools that are useful later but not urgent now. This is the distinction I’d use.
| Need to have | Nice to have |
|---|---|
| Python for analysis | Deep learning frameworks |
| SQL for joins and aggregations | Distributed systems depth |
| Statistics fundamentals | Cloud certifications |
| Data cleaning discipline | Advanced MLOps tools |
| Basic model evaluation | Cutting-edge model architectures |
| Clear communication | Complex deployment stacks |
That doesn’t mean the right column is irrelevant. It means the left column gets you interviews for junior work. The right column only helps if the basics are already obvious.
The overlooked skill that decides interviews
Communication is where many junior candidates separate themselves. Not polished presentation. Simple, structured explanation.
You need to answer questions like:
- What problem were you solving
- How did you prepare the data
- Why did you choose that method
- What did you find
- What would you do next
That’s the job. Not just coding.
A junior who says, “I used XGBoost because it performs well” sounds shallow. A junior who says, “I started with a simple baseline, checked for leakage, compared results, and chose the more interpretable option because the use case involved non-technical stakeholders” sounds employable.
Building a Standout Data Science Portfolio
Most portfolios fail for a simple reason. They’re built like coursework, not like evidence.
Hiring managers don’t need another repository called customer-churn-project-final-v2 with a dense notebook and no explanation. They need proof that you can frame a problem, make choices, and communicate results. Your portfolio is less like a museum and more like a sales asset. It should do the marketing for you before anyone speaks to you.
Stop building projects that look interchangeable
A lot of junior portfolios blend together because they use the same datasets, the same notebooks, and the same shallow framing. The issue isn’t that common datasets are forbidden. The issue is that common projects make it harder to show independent judgment.
A stronger portfolio answers questions like:
- Why did you choose this problem
- Who would care about the result
- What trade-offs did you make
- What limitations did you identify
- What action should someone take next
That’s how you stop looking like a student and start looking like a junior professional.
What a useful portfolio project looks like
A solid project has a simple structure:
| Part | What it should show |
|---|---|
| Problem statement | You understand a business or operational question |
| Data section | You can gather, inspect, and clean data responsibly |
| Method | You chose an approach on purpose |
| Results | You can summarize findings clearly |
| Limitations | You understand uncertainty and constraints |
| Recommendation | You can connect analysis to action |
This doesn’t require a flashy app. A well-structured repository with a crisp README can outperform a more advanced project that’s confusing to review.
Three project ideas that signal real judgment
Operational forecasting for a local service
Take public or self-collected data related to bookings, foot traffic, deliveries, or appointment demand. Build a project that forecasts workload and recommends staffing decisions.
What makes this good is the business logic. You’re not just predicting a number. You’re showing that forecasts exist to support decisions. Include missing data handling, outlier discussion, and what errors would matter operationally.
Healthcare access or wait-time analysis
Use a public healthcare dataset and focus on access, delays, or service patterns. Don’t treat this as a leaderboard competition. Treat it as a constrained problem where interpretability matters.
That gives you room to discuss ethics, bias, data quality, and why a simple model might be better than a more complex one.
Financial behavior segmentation
Build a segmentation or risk-oriented analysis from financial or transactional style data. Even if the data is synthetic or public, frame it around practical use cases like prioritizing account review, identifying usage patterns, or understanding retention risk.
This works well because it lets you show SQL, exploratory analysis, feature thinking, and communication.
A portfolio project should answer, “Would I trust this person with a small real problem?” not “Can this person import a library?”
Your README matters more than your notebook
A junior mistake I see often is hiding the story inside code. Reviewers don’t want to excavate your thinking from scattered cells and long outputs.
Your README should make the project easy to understand in a few minutes. Include:
- A clear business question
- A short summary of the dataset
- Your workflow
- A few key findings
- A section on limitations
- Instructions for running the project
If your repository is messy, people will assume your working style is messy.
A useful walkthrough on presenting project work more clearly is below.
Show process, not just outcomes
A lot of junior candidates think the result has to be impressive. It doesn’t. The reasoning has to be credible.
You gain points when you document decisions such as:
- Why you removed or kept a feature
- Why you started with a baseline
- Why a simpler model was acceptable
- Why a metric fit the use case
- Why the data limited confidence
Those details show maturity.
If you want your portfolio to stand out, aim for fewer projects with better framing. Three thoughtful case studies beat a pile of unfinished experiments. A hiring manager is often looking for evidence that you can finish a piece of work, defend your choices, and communicate the result to someone who doesn’t care about your notebook style.
Creating Your Job-Winning Application Toolkit
A junior application usually fails before a human ever sees it. That’s why your toolkit has to do two jobs at once. It must survive automated filtering and make a strong impression once a recruiter or hiring manager opens it.
The ATS part isn’t optional. Resumes need keywords from the job description to pass filters. In 2025, the most common keywords were machine learning (69%), SQL (60%), and Python (57%), and 365 Data Science reports that unoptimized resumes have a callback rate below 5%, compared with 25% to 30% for keyword-matched resumes.
Your resume should read like evidence
The biggest resume mistake juniors make is listing tools without context. “Python, SQL, Pandas, Tableau, scikit-learn” tells me almost nothing. I need to know what you did with them.
A better approach is to organize your resume around proof:
Header and summary
Keep this simple. Name, contact details, GitHub, LinkedIn, and if relevant, a portfolio site. Your summary should be short and specific.
Bad summary: “Motivated aspiring data scientist passionate about leveraging data-driven insights.”
Better summary: “Junior data candidate with hands-on project work in Python, SQL, and machine learning, focused on data cleaning, exploratory analysis, and business-oriented modeling.”
The second one sounds like a person who has done work.
Projects section
For many juniors, this is the heart of the resume. Treat it that way.
Each project bullet should include:
- What problem you addressed
- What tools you used
- What you built or analyzed
- What decision or insight came from it
You don’t need to stuff in numbers if you don’t have verified ones. Clear outcomes still work. For example, “Built a customer segmentation analysis in Python and SQL, created visual summaries for non-technical review, and documented trade-offs between interpretability and model complexity.”
Skills section
Keep this honest. Split it if needed:
| Category | Example content |
|---|---|
| Languages | Python, SQL, R |
| Libraries | pandas, scikit-learn, matplotlib, seaborn |
| Data skills | cleaning, EDA, feature engineering, model evaluation |
| Tools | Jupyter, Git, Tableau or Power BI |
Don’t claim tools you can’t discuss comfortably in an interview.
GitHub and LinkedIn need to work together
Your resume gets attention. GitHub confirms substance. LinkedIn helps you be discoverable and credible.
What a strong GitHub profile looks like
Pin a small set of your best repositories. Don’t pin everything. Curate.
Make sure each featured repo has:
- A meaningful title
- A readable README
- Clean folder structure
- Requirements or setup notes
- Clear notebooks or scripts
- No abandoned “coming soon” mess
A weak GitHub profile creates doubt. A clean one reduces it.
LinkedIn should mirror the jobs you want
Write your headline for search, not for ego. “Aspiring data scientist” is vague. Something closer to “Junior Data Scientist | Python, SQL, Machine Learning | Portfolio Projects in Forecasting and Segmentation” is much stronger.
Then align your About section, skills, and featured links with your target roles. Recruiters and hiring teams often compare your resume to your LinkedIn quickly. If they tell different stories, that hurts trust.
Hiring signal: Consistency matters. If your resume says machine learning and your GitHub shows only half-finished dashboards, people notice.
Tailor every application without rewriting from scratch
You don’t need a new resume for every single role. You do need a system.
Use a master resume, then customize the top half and project bullets based on the posting. Pull exact phrases from the description where they truthfully apply. If the role emphasizes SQL and data preparation, that should appear clearly in your version. If it stresses business communication, your bullets should show presentation or stakeholder-facing work.
A practical workflow looks like this:
- Save a master resume
- Highlight repeated phrases in the job description
- Match those phrases to your actual experience
- Reorder bullets to fit the role
- Check that your resume, LinkedIn, and GitHub tell the same story
That’s not gaming the system. That is clear communication.
How to Find Remote Data Science Jobs Before Anyone Else
The standard job-board workflow is broken for a lot of junior candidates. You search on LinkedIn or Indeed, open a role that looks promising, and find a listing that may already be old, overloaded, or buried in recruiter noise. By the time job seekers see a good remote role, the application pile is already ugly.
That’s why a first-mover strategy matters. For remote work especially, timing isn’t a minor edge. It changes the whole competition level you face.
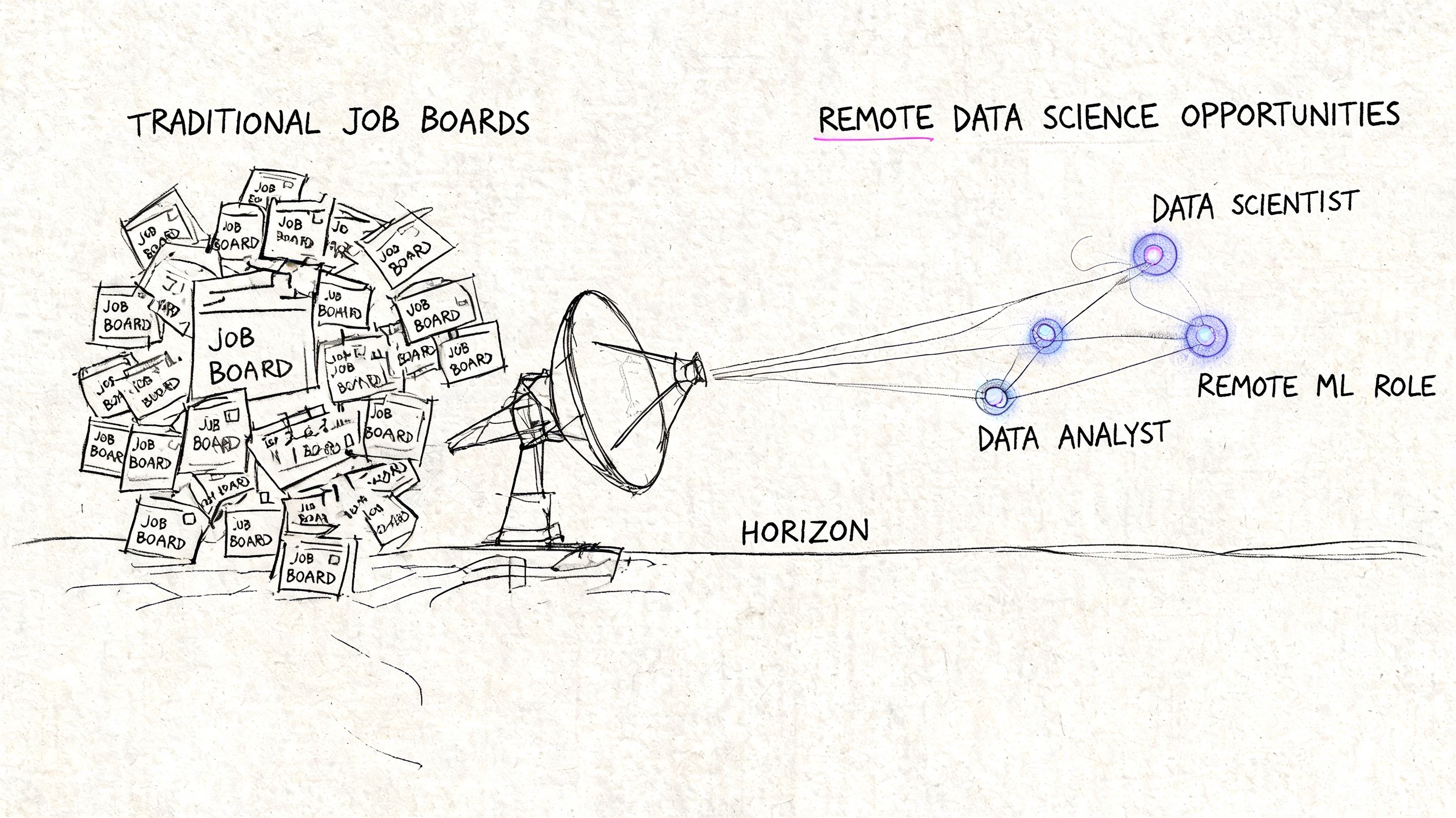
Why major job boards create noise
The main problem with giant job boards isn’t that they never work. It’s that they create a public feeding frenzy.
Once a good remote junior role gets broad visibility, several things happen fast:
- Application volume spikes
- Late applicants start blending together
- Generic resumes flood the same queue
- You spend time sorting weak listings from real ones
A lot of beginners respond by applying to more roles. That feels productive, but often lowers quality. They submit rushed applications, skip tailoring, and arrive late anyway.
The better move is to change the source of discovery.
What first-mover search looks like in practice
The strongest remote job search I’ve seen from junior candidates looks less like casual browsing and more like targeted monitoring. Instead of checking giant boards at random times, they track remote-first companies, watch career pages, and apply when listings are still fresh.
That creates a quieter window. In that window, your application has a better chance of being evaluated before the role becomes a pile.
A tool built around that idea is Remote First Jobs, which focuses on remote roles pulled directly from company career pages rather than relying on the usual noisy aggregation path. That direct-sourcing model fits the way serious applicants should think about timing.
Apply while a posting is still new enough for someone to read it with attention. That’s the edge.
A practical search system for junior roles
If you want this to work, build a routine rather than relying on motivation.
Search by role family, not just title
Junior data roles often appear under several titles. Don’t limit yourself to one phrase. Track variants like data analyst, product analyst, analytics engineer, junior data scientist, and business intelligence roles when the skill overlap is real.
Focus on the work described, not just the label.
Prioritize remote-first companies
Remote-first teams usually communicate their hiring process more clearly than companies treating remote work as an exception. That matters when you’re trying to move quickly and avoid dead ends.
You also reduce friction when the company already knows how to onboard distributed workers.
Apply early, then follow through properly
Speed only helps if the application is good. Don’t send the same resume blindly. Have a prepared toolkit so you can tailor and submit quickly without sacrificing quality.
A simple cadence works well:
| Step | What to do |
|---|---|
| Discovery | Review fresh roles from company-origin sources |
| Screening | Check fit on skills, scope, and basic requirements |
| Tailoring | Match resume and headline keywords to the posting |
| Submission | Apply promptly through the company’s process |
| Follow-up | Track the role and prepare for a fast response |
The unfair advantage most juniors ignore
Most candidates think the edge comes from one more certification or one more course. Those things can help, but they’re not usually the biggest advantage once your fundamentals are decent.
The larger edge is this: finding strong roles before they become crowded and being ready to act immediately.
That’s especially important in remote hiring because applicants from many locations can converge on the same posting very quickly. If you’re late, your quality has to overcome volume. If you’re early, your quality gets seen before volume dominates.
For a data science junior, that’s a real strategic difference. Not because early application guarantees success. It doesn’t. It gives your work a fairer chance to be evaluated on merit instead of being buried.
Passing the Data Science Interview and Technical Challenge
Interviews feel unpredictable when you haven’t seen the pattern yet. Once you understand the sequence, they become much easier to prepare for. Most junior data interviews test the same core things in different forms: can you reason clearly, can you work with data, can you communicate trade-offs, and can people imagine working with you.
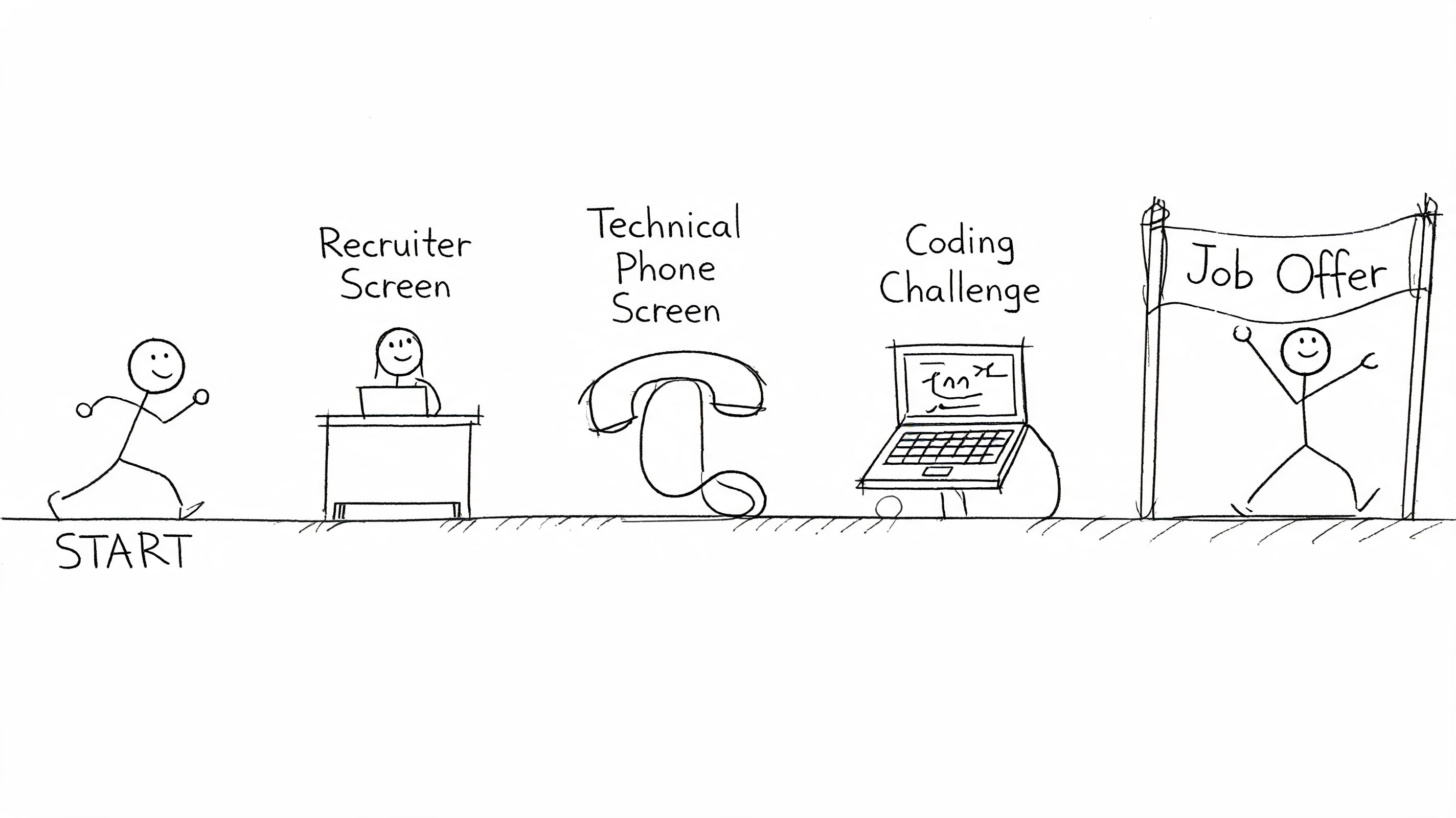
The recruiter screen
This round isn’t mainly technical. It checks whether you make sense for the role on paper and in conversation.
Expect questions like:
- Tell me about yourself
- Why this role
- Why data science
- What kinds of projects have you worked on
- What are you looking for in your first role
The mistake here is rambling. Keep your answers structured. You want a clear narrative: background, transition into data, what you’ve built, and the kind of problems you want to solve.
A solid answer sounds grounded. It connects your learning path to actual work you’ve done and shows you understand what a junior role involves. It doesn’t try to sound like a senior candidate.
The technical screen
This stage often covers SQL, Python, statistics, and analytical reasoning. The company may not test all of them extensively, but they usually want signs of competence across the basics.
SQL questions
Be ready for joins, grouping, filtering, and basic analytical logic. Sometimes the question isn’t hard syntically. The hard part is understanding the business request.
For example, if asked to identify users whose activity dropped after a feature launch, start by clarifying definitions. What counts as activity? What time window matters? What comparison is fair?
That kind of thinking impresses interviewers more than rushing into code.
Python questions
Expect small tasks such as cleaning a dataframe, transforming columns, handling nulls, or explaining how you’d structure an analysis pipeline. Sometimes they’ll ask for pseudocode or reasoning instead of perfect implementation.
Interviewers watch for:
- Clarity
- Basic correctness
- Choice of approach
- Ability to explain trade-offs
If you freeze when coding live, narrate your thinking. Silence makes people assume you’re lost. Clear reasoning buys you credibility even when you need a moment.
Statistics and modeling questions
These questions often sound simple but expose shaky understanding fast. You might be asked about overfitting, evaluation metrics, feature leakage, class imbalance, or why one model is preferable to another.
Don’t answer like you’re reciting flashcards. Tie your answer to practical use. For example, instead of defining precision abstractly, explain when false positives are especially costly and why that affects metric choice.
Strong junior candidates don’t pretend certainty. They explain assumptions, caveats, and what they’d check next.
The take-home challenge
A take-home is where many good candidates lose points through poor packaging. They focus only on getting an answer and ignore how the work is delivered.
Treat a take-home like a miniature consulting engagement.
A strong approach to take-homes
- Read the prompt twice
Separate required outputs from optional ideas. Don’t build extra complexity that steals time from clarity.
- Define the question in your own words
Write a short note at the top of your notebook or README stating the problem and your approach. This helps the reviewer follow your logic.
- Keep the workflow clean
Organize the work into loading, cleaning, exploration, modeling if relevant, and conclusions. Messy notebooks create friction.
- Document decisions
Explain why you dropped columns, how you handled missing values, why you chose a baseline, and what limitations remain.
- End with recommendations
Many juniors stop at charts or model output. Go one step further. State what the team should do next or what data would improve confidence.
A neat, readable submission often beats a more advanced but chaotic one.
Behavioral interviews and project deep dives
Judgment often gets tested. You’ll likely be asked about teamwork, conflict, mistakes, priorities, and how you handled ambiguity in a project.
Use the STAR method:
| Part | What to include |
|---|---|
| Situation | Brief context |
| Task | What you were responsible for |
| Action | What you actually did |
| Result | What happened and what you learned |
Keep the “Action” part longest. Too many candidates spend most of the answer on background and rush the interesting part.
For project deep dives, know your own work well enough to discuss:
- Why you picked the problem
- How you cleaned the data
- Why you selected that method
- What failed or changed
- What you would improve
- What trade-offs mattered
Here, fake understanding gets exposed. If the project is yours, you should be able to discuss dead ends, constraints, and decisions without sounding rehearsed.
Questions you should ask them
The end of the interview matters more than many juniors think. Good questions signal maturity and help you avoid bad roles.
Ask things like:
- What does success look like for a junior in the first few months
- What kind of problems would this person work on first
- How are projects scoped and reviewed
- Who would I learn from most closely
- How does the team balance speed with analytical rigor
These questions do two things. They show that you’re thinking like someone who wants to contribute, and they reveal whether the company supports junior growth.
What works versus what doesn’t
Here’s the practical version.
| Works | Doesn’t work |
|---|---|
| Explaining trade-offs clearly | Hiding behind jargon |
| Starting with a baseline | Jumping to the fanciest model |
| Admitting uncertainty thoughtfully | Pretending to know everything |
| Telling the story of a project | Reading bullets from memory |
| Clean code and documentation | Dense notebooks with no structure |
| Asking clarifying questions | Solving the wrong problem confidently |
A final point that matters. Interview performance improves fastest when you practice out loud. Not in your head. Speak through project summaries, SQL logic, metric choices, and behavioral stories until your answers sound natural rather than memorized.
Most junior interviews don’t require brilliance. They require reliable thinking under light pressure. If you can stay calm, structure your answers, and make your reasoning visible, you’ll already be ahead of a large part of the field.
If you’re tired of crowded job boards and want a cleaner way to find remote roles early, Remote First Jobs is worth a look. It focuses on direct-from-company remote listings, which fits the first-mover strategy far better than waiting for the same roles to spread across noisy public platforms.
